前提
因产品需求,需用 PHP(v7.0.12)调用 k8s 集群中 gRPC([email protected])服务。
问题
经过 dev 环境测试,当 php-fpm 启动后第一次调用或者距离上次调用时间 20 分钟后左右,再次请求 gRPC 微服务接口,就会返回 Connection reset by peer 错误,说明 gRPC 服务端或者客户端主动关闭连接了。继续发起请求到服务端,又恢复正常。

思考
经查阅相关资料,发现问题可能出现在 k8s 集群的 kube-proxy 模式上。当前 k8s 环境 (dev) 下的 kube-proxy 为 ipvs 模式,服务端与客户端之间通信如下:
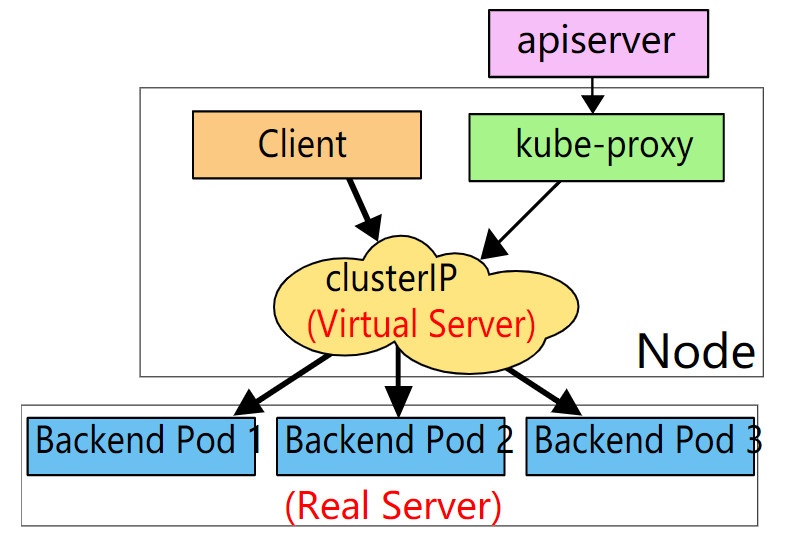
把上图 client 看成是 apsopen-inside 服务 pod,Backend pod(1~3) 看成 gRPC 服务,可以看出它们之间的交互路径:
---> gRPC server pod1
gRPC-client ---> ipvs ---> gRPC server pod3
---> gRPC server pod3
我们知道gRPC是基于HTTP/2协议的,gRPC的client和server在交互时会建立多条连接,为了性能,这些连接都是长连接并且是一直保活的。这段环境中不管是客户端服务还是 gRPC 服务都被调度到各个相同配置信息的 Kubernetes 节点上,这些 k8s 节点的 keep-alive 是一致的,如果出现连接主动关闭的问题,因为从 client 到 server 经历了一层 ipvs,所以最大的可能就是 ipvs 出将连接主动断开,而 client 端还不知情。 搜索 ipvs timeout 关键字找到了下面相关的链接:
- https://github.com/moby/moby/issues/31208
- https://success.docker.com/article/ipvs-connection-timeout-issue
- https://github.com/kubernetes/kubernetes/issues/32457
其中 https://github.com/moby/moby/issues/31208 中是关于 docker swarm 在 overlay 网络下长连接的问题,这个和 k8s kube-proxy 应该是类似的,按照这个链接中的描述查看 我们这套环境关于 tcp keepalive 的内核参数:
#进入igo-util-shorturi容器
sysctl net.ipv4.tcp_keepalive_time net.ipv4.tcp_keepalive_probes net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_intvl = 75
上面这段参数的含义:net.ipv4.tcp_keepalive_time 是连接时长,当超过这个时间后,每个 net.ipv4.tcp_keepalive_intvl 的时间间隔会发送 keepalive 数据包,net.ipv4.tcp_keepalive_probe 是发送 keepalived 数据包的频率。
解决
使用 ipvsadm 命令查看 k8s 节点上 ipvs 的超时时间:
ipvsadm -l --timeout
Timeout (tcp tcpfin udp): 900 120 300
可以看出,各个 k8s 节点上 tcp keepalive 超时是 7200 秒 (即 2 小时),ipvs 超时是 900 秒 (15 分钟),这就出现如果客户端或服务端在 15 分钟内没有应答时,ipvs 会主动将 tcp 连接终止,而客户端还以为超时间依然是 2 个小时。很明显 net.ipv4.tcp_keepalive_time 不能超过 ipvs 的超时时间。
调节 k8s 节点上的 tcp keepalive 参数如下:
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
再去测试 Connection reset by peer 问题已经解决。